![]()

1 Northeastern University, 2 Singapore University of Technology and Design,
3 Nanjing University of Science and Technology
{yangxiaocui, wenfang}@stumail.neu.edu.cn,
{fengshi, wangdaling, zhangyifei}@cse.neu.edu.cn,
{pengfei_hong, sporia}@sutd.edu.sg, 319106003718@njust.edu.cn
论文链接:https://arxiv.org/pdf/2305.10169.pdf
代码链接:https://github.com/YangXiaocui1215/GMP
作者:杨晓翠1,2,冯时1,王大玲1,孙琦3,武文芳1,张一飞1,洪鹏飞2,Soujanya Poria 2
单位:1东北大学,2新加坡科技与设计大学,3南京理工大学
收录:Findings of ACL 2023
1.摘要
传统研究通常需要大量标记数据来训练基于方面的多模态情感分析(MABSA)模型。然而,随着多模态数据在广泛的社交媒体平台上的迅速扩增,为MABSA收集和注释细粒度的多模态数据非常困难。为了缓解上述问题,我们使用少量的有标签的多模态数据进行执行三个与MABSA相关的任务。我们首先根据数据集的分布构建多样且全面的多模态小样本数据集。同时,为了在小样本场景中捕获每个方面项的特定提示,我们为MABSA任务提出了一种新颖的生成式的多模态提示(GMP)模型,其中包括多模态编码器模块和N-Stream解码器模块。我们进一步引入了一个子任务来预测每个实例中方面项的数目,从而构建多模态提示。我们在两个数据集上进行的大量实验,在小样本设置中,实验结果表明我们的方法在两个MABSA相关的任务上优于强基线。

图1:少量样本设置中针对MASC和JMASA的提示示例
基于方面的多模态情感分析(MABSA)任务最近引起了广泛关注。MABSA通常分为三个子任务:多模态方面项提取(Multimodal Aspect Term Extraction, i.e., MATE)、面向方面的多模态情感分类(Multimodal Aspect-oriented Sentiment Classification, i.e., MASC)和联合多模态方面-情感分析(Joint Multimodal Aspect-Sentiment Analysis, i.e., JMASA)。给定一个文本-图像对,MATE旨在提取文本中的所有的方面项,MASC专注于检测与每个方面项对应的情感,而JMASA旨在联合提取方面项及其对应的情感。起初,基于方面的多模态情感分析(MABSA)的研究主要集中在利用大量的训练数据(完整的训练数据集),后来一些工作利用额外的数据来提高性能。然而,为MABSA收集和注释大规模的多模态数据既费时又费力。此外,在实际应用中,通常只有有限的数据有标签。为了应对这一挑战,PVLM和UP-MPF在小样本场景中将基于提示的学习引入到面向方面的多模态情感分类(MASC)中。基于有限的情感类别(三类),PVLM和UP-MPF将MASC转换为掩码语言建模(MLM)任务。然而,MASC的前提是方面项是已知的,这需要先通过MATE或JMASA提取方面项。由于每个样本中的方面项未知且数量不定,且每个aspect的内容也各不相同,从而JMASA和MATE任务更具有挑战性。因此,在小样本设置中,将JMASA和MATE任务转换成MLM任务是不合适的。据我们所知,在多模态小样本场景中目前未见专门的研究来处理JMASA和MATE任务。先前的工作为具有有限分类标签的小样本文本分类任务手动设计了不同的提示,以从预训练语言模型(PLM)中挖掘知识,如图1所示。然而,在联合多模态方面情感分析(JMASA)和多模态方面项提取(MATE)的任务中,每个方面项的内容是未知且各异,为方面项提取相关的任务设计手动提示是不可行的。我们的工作旨在解决 JMASA、MASC 和 MATE 在文本-图像小样本设置中的挑战。
2. 模型
为了应对以上提到挑战,我们提出了一种新的生成多模态提示(GMP)模型,用于小样本多模态基于方面的情感分析(MABSA),其中包括多模态编码器(ME)模块和N-Streams解码器(NSD)模块,如图2所示。
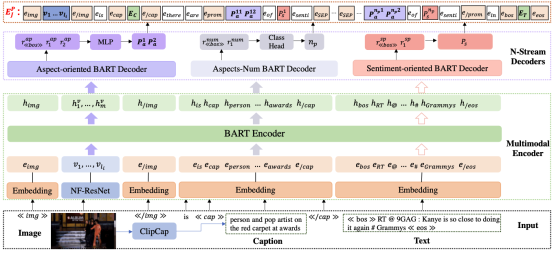
图2:用于基于生成多模式提示(GMP)的多模态方面情感分析框架包括两个主要模块:多模态编码器模块(绿色虚线框)和N-Stream解码器模块(紫色虚线框)
在多模态小样本设置中,采样数据以构建对多样且全面的小样本数据集至关重要。为此,我们根据数据分布,通过对实例中不同情感组合的数据进行采样来构建小样本训练数据集和验证数据集,同时测试集保持不变,如表1所示。由于JMASA和MATE中的方面项的数量未知且重要,我们利用Multimodal Encoder(ME)和Aspect-Num Decoder(AND)来预测方面项的数量作为子任务。由于实例的各个方面所需的线索可能会有所不同,为此我们使用ME和Aspect-oriented Prompt Decoder(APD)为每个方面生成面向方面的提示(方面级别)。类似地,我们使用ME Sentiment-oriented Prompt Decoder(SPD)来生成面向情感的提示。由于所有数据集中的情感类别都是有限的,为此我们只保留实例级的情感提示。图像模态的caption也被捕获为图像提示。基于图像提示、方面术语的预测数量、方面提示和情感提示,构建针对不同任务的特定多模态提示。我们将带有多模态示的多模态嵌入输入到基于多模态编码器-解码器的BART模型中,以生成三元组序列,如图3所示。

图3:JMASA 任务的三元组序列生成示例
我们根据表1所示的Twitter-15(15)和Twitter-17(17)的情绪类别分布构建的两组小样本多模态数据集并在三个任务上进行实验,包括多模态方面项提取(MATE)、面向方面的多模态情感分类(MASC)和联合多模态方面-情感分析(JMASA)。
3.1 数据集
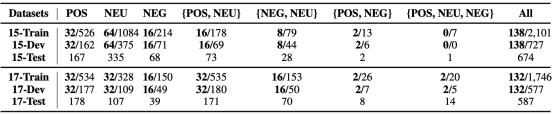
表1:两个数据集的统计数据
3.2 实验结果和分析
3.2.1 JMASA任务结果及分析

表2:不同模型在MABSA的精度(P)、召回率(R)和F1方面的平均结果
JMASA任务在小样本多模态数据集上的结果如表2所示,从该表中可以得出几个关键结果。首先,多模态模型通常优于单模态模型。在多模态模型中,与不涉及预训练任务的 NVLP相比,JML和VLP分别利用额外的数据进行关系检测和预训练,取得了更好的性能,表明预训练任务提高模型性能。当考虑模型使用的数据量时,将我们的模型与NVLP进行对比更为合理。我们的模型在两个数据集上始终优于NVLP,表明其卓越的性能。值得注意的是,我们的模型在Twitter-15和Twitter-17数据集上也明显优于次优的模型VLP的F1绝对百分比分别为1.56和2.03。我们模型的卓越性能可以归因于几个因素:首先,基于多模态上下文的生成式多模态提示使模型能够从预训练的语言模型中捕获每个样本的实用知识;其次,子任务信息为构建多模态提示提供了有价值的线索,从而提高了小样本多模态情感分类的性能。
3.2.2 MASC任务结果及分析
MASC任务在小样本多模态数据集上的准确性(Acc)的结果如表2所示。可以从该表结果中可以观察到,在多模态小样本设置中:1)我们的模型在多模态小样本设置中表现出最佳性能,表明它在处理有限标记数据的挑战方面优于其他模型;2)基于提示的方法优于稳健的多模态模型,突出了基于提示的方法在低资源场景中的有效性。这表明利用提示工程技术,例如我们的生成多模式提示,可以提高小样本MSA的性能;3)仅使用文本模态的BART比大多数多模态模型表现更好,表明我们的基础模型具有强大的性能,同时也表明预训练语言模型BART为我们的多模态模型提供了坚实的基础。

表3:不同模型在两个数据集上的MASC任务上的Acc结果( “*”表示该模型是针对小样本任务提出的)
3.2.3 MATE任务结果及分析
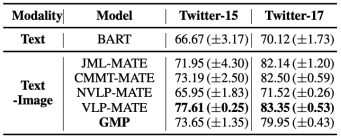
表4: 不同模型在两个数据集上的MATE任务上的F1结果
表4显示了MATE任务的结果。在这些模型中,VLP在MATE中取得了最好的性能,尽管它偏离了我们最初应用低资源数据的目标,因为它依赖于额外的数据和在MVSA-Multiple数据集上的多个预训练任务。同样,JML也利用额外的数据来增强其性能。一个有趣的现象是,NVLP在MASC任务上表现的更好,VLP在MATE和JMASA任务上有更好的表现。我们猜测这是因为VLP的预训练任务可能更符合MATE任务,这反过来可能会对MASC的性能产生影响。
3.2.4 消融实验
我们对GMP模型进行了消融实验,以评估不同模块的有效性,如表5所示,结果表明完整的GMP模型在所有任务中始终具有最佳性能。首先,我们删除图像模态(无图像)并仅基于文本模态构建生成提示。该模型在所有任务中的性能都受到影响,表明图像模态对于在小样本MSA任务中实现高性能至关重要。接下来,我们只去除图像标题(w/o Caption)并保留初始图像特征来评估图像提示的有效性。结果表明,图像提示有助于模型的整体性能,其在从图像模态中捕获重要信息方面的实用性。我们还进行了删除多任务模块(w/o Multitask)的实验,并将 JMASA和MATE任务中每个实例的方面项的数量设置为5。模型的性能受到影响,表明特定于子任务的模块在捕获方面相关信息和提高性能方面是有效的。为了验证生成多模态提示的实用性,我们删除了多模式提示(w/o Prompt)并仅使用原始文本图像表示。该模型的性能下降,表明我们提出的多模式提示有利于为情感分析任务提供有价值的线索。我们进一步删除生成方面提示(w/o GAP)以评估GAP的重要性。有趣的是,我们观察到使用生成的情绪提示(GSP)在MASC任务(w/o GSP)中获得更好的性能,而我们在JMASA任务(w/GSP)中获得相反的结果,这表明生成的方面提示为模型提供了足够的信息,而GSP可能会在JMASA任务中引入冗余信息。然而,在MASC任务中,GSP为情感分类提供了有效的线索。我们进一步试验不同生成的情绪提示(w DSPrompt),发现性能显著下降,这种现象有两个可能的原因:首先,我们数据集中的情感类别是有限的,当为每个方面使用生成的情感提示时,它可能会向MASC引入噪音和不相关的信息;其次,为每个方面生成的提示提供了足够的信息来指导模型捕获与方面相关的情感信息。

表 5:在两个数据集上,JMASA和MATE任务消融实验的F1结果以及MASC任务消融实验的Acc结果(“w/”表示“with”,“w/o”表示“without”)
我们提出了一个用于解决方面的多模态情感分析(MABSA)任务的生成式多模态提示(GMP)模型,包括多模态小样本场景中的JMASA、MASC和MATE。我们进一步引入一个子任务来预测方面项的数量,从而形成多任务训练以提高GMP的性能。实验结果表明,我们提出的方法在小样本设置中优于MABSA的两个子任务的强基线模型。我们在小样本设置中为MABSA的相关任务提供了新的方向。在未来的工作中,我们计划利用细粒度图像特征并实现文本和图像模态之间的对齐,以提高在多模态小样本场景中MABSA的性能。
作者简介

杨晓翠,东北大学计算机科学与技术专业在读博士。研究方向为多模态情感分析,多模态关系分类等,参与多项国家自然科学基金等。

冯时,东北大学计算机科学与工程学院计算机科学系副教授,博士生导师。目前担任中国中文信息学会情感计算专委会委员,中国中文信息学会社会媒体处理专委会委员,中国中文信息学会青年工作委员会委员。主要从事情感分析与对话系统方向的研究。作为项目负责人承担(完成)国家自然科学项目3项,近年来在计算机学会A类/B类期刊会议发表论文40余篇,获得辽宁省科技进步二等奖,《计算机学报》2017-2021年度优秀论文奖。

王大玲,东北大学计算机科学与工程学院计算机科学系教授、博士生导师。中国中文信息学会社会媒体处理专业委员会常务委员,中国中文信息学会情感计算专业委员会委员,中国计算机学会自然语言处理专业委员会委员。目前的研究领域包括社会媒体处理、情感分析、对话生成等。

张一飞,东北大学计算机科学与工程学院计算机科学系讲师。 CCF 专业会员, 主要研究领域为机器学习, 视觉处理。

