
IJCAI 2022:一种用于对话情绪识别的因果感知交互网络
论文链接:https://www.ijcai.org/proceedings/2022/628
论文代码:https://github.com/circle-hit/CauAIN
论文作者:赵伟翔、赵妍妍、陆鑫
单位:哈尔滨工业大学
1.动机介绍
对话情绪识别(Emotion Recognition in Conversations, ERC)旨在预测一段对话中每条对话语句的情感。由于其在实现共情对话系统中扮演着重要的角色,以及ERC在观点挖掘、社交媒体分析、精神健康等其他领域有着广泛的应用,对于该任务的研究近年来在自然语言处理社区备受关注。ERC任务的关键挑战在于对话中的情感动态(Emotional Dynamics),指的是对话中说话人之间的情感交互。为了解决这一挑战,之前的工作致力于利用循环神经网络(Recurrent Neural Network, RNN)和图卷积神经网络(Graph Convolutional Network, GCN)建模说话人自身(Intra-speaker dependency)和说话人之间(Inter-speaker dependency)的依赖关系。然而,这种建模受限于无法捕捉对话语境中深层且丰富的情感动态变化线索,因为对话中真正导致情绪产生的原因被忽略了。我们认为,如果模型具有将当前目标句与产生其情绪的原因语句进行关联的能力,那么它将能够更好的理解人类情感。
对于表示说话人情绪原因的对话语句,我们将其分为自身原因语句(Intra-cause utterance)和他人原因语句(Inter-cause utterance)。前者指的是出现在说话人自己的对话回合中的,这意味着情绪的原因是由于说话人从以前的情绪状态中继承下来的稳定情绪,而后者则出现在其他说话人的回合中,目标说话人的情绪是受到其他说话人的影响。图1展示了一个例子,说明借助于识别对话中的这两种原因语句来进行情绪识别。

2. 模型方法
为了提取更丰富的情感动态线索,我们提出了因果感知交互网络(Casual Aware Interaction Network, CauAIN),从情绪原因检测的角度对说话者内部和之间的依赖关系进行明确建模。由于没有标注情绪原因标签的ERC数据集,我们利用常识性知识作为对话中情绪原因检测的因果线索。更具体地来讲,我们根据因果关系考虑了外部知识库ATOMIC(The Atlas of Machine Commonsense)中的六种if-then关系类型。xReact、xEffect和xWant被视为自身原因线索,而oReact、oEffect和oWant被解释为他人原因线索。为了识别目标语句所表达的某种情绪的原因,我们设计了一个由因果线索检索和因果语句回溯组成的两步因果意识交互过程。首先,不同的自身原因和他人原因的线索会根据它们对目标语句的影响进行评估。然后,上一步的结果可以被看作是因果语篇内和因果语篇间回溯的阈值。在最后的分类层中,因果意识表征被混合用于情感识别。
CauAIN的结构如图2所示,它由四个部分组成。因果线索获取、因果线索检索、因果语句回溯和情感识别。我们将在本节的其余部分对它们逐一进行阐述。
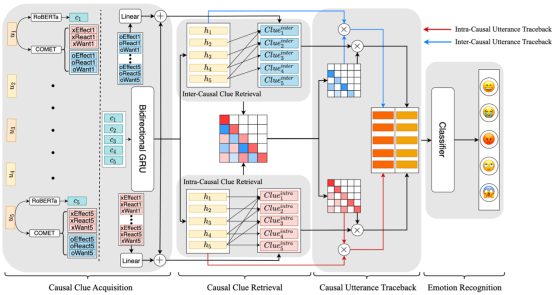
2.1 因果线索获取
2.2.1自身原因和他人原因的线索表示
由于现有ERC数据集中没有标注情绪原因,我们利用ATOMIC提供因果线索。
什么是ATOMIC?ATOMIC是一个日常常识性推理的图谱,通过推理知识的文本描述来组织,其中提出了九种if-then关系类型来区分原因与结果、代理人与主题、自愿与非自愿事件以及行动与心理状态。
为什么我们选择ATOMIC?之前的工作证明了神经网络能够在ATOMIC提供的丰富推理知识的帮助下,对之前未见过的事件的可能原因和效果进行预测。据此,我们在对话的场景下扩展了这种未见过的事件,并探索了六种关系类型,这些关系都根据其因果关系被归类为 “影响”。具体来说,xReact、xEffect和xWant提供了自身原因内的线索,代表了由说话人自己的话语所产生的影响或结果。此外,oReact、oEffect和oWant意味着对他人产生了什么影响,或者他人在接受了当前的话语后想做什么,想感受什么。因此,如果我们考虑到这三种关系类型,就可以发现丰富的因果关系线索。图3显示了与上述六种关系类型相对应的因果线索。

如何从ATOMIC获得因果线索?为了获取ATOMIC中包含的因果关系内和因果关系间的线索,我们采用了在ATOMIC上训练的生成性常识Transformer模型COMET。给定输入的事件(在对话的情况下被称为语句![]() )和选择的关系类型,COMET将以if-then推理的格式生成then的描述。例如,将
)和选择的关系类型,COMET将以if-then推理的格式生成then的描述。例如,将![]() 和关系类型oReact作为输入,COMET可以得出“如果
和关系类型oReact作为输入,COMET可以得出“如果![]() ,那么其他人就会感到”的推理序列。我们将
,那么其他人就会感到”的推理序列。我们将![]() 和关系与掩码标记连接起来,如(
和关系与掩码标记连接起来,如(![]() [MASK] oReact)来构建COMET的输入。我们将COMET最后一个编码器层的隐藏状态代表被作为因果线索。因此,在这项工作中,对于每个
[MASK] oReact)来构建COMET的输入。我们将COMET最后一个编码器层的隐藏状态代表被作为因果线索。因此,在这项工作中,对于每个![]() ,从COMET中产生的三条自身原因线索被拼接起来,并以线性变换映射到
,从COMET中产生的三条自身原因线索被拼接起来,并以线性变换映射到![]() 的维度。其他三条他人间的原因线索也是如此。我们把它们表示为
的维度。其他三条他人间的原因线索也是如此。我们把它们表示为![]() 和
和![]()
2.2.2对话语句表示
我们采用广泛使用的预训练模型RoBERTa来提取对话语句级别的特征向量。具体来说,对于每条对话语句![]() ,我们在语句的开始部分设置一个特殊的标记[CLS]。然后,序列
,我们在语句的开始部分设置一个特殊的标记[CLS]。然后,序列![]() 被送入预训练的RoBERTa模型,进行对话语句情感分类任务的微调,最后一层的[CLS]标记通过池化层,将其分类到其情感类别。
被送入预训练的RoBERTa模型,进行对话语句情感分类任务的微调,最后一层的[CLS]标记通过池化层,将其分类到其情感类别。
在微调过程之后,为了得到对应于[CLS]标记的对话语句级特征向量![]() ,我们将每条对话语句以相同的输入格式
,我们将每条对话语句以相同的输入格式![]() 传递。
传递。
![]() = RoBERTa(
= RoBERTa(![]() )
)
其中![]() ∈
∈![]() ,
,![]() 是RoBERTa中向量的隐藏状态的维度。我们将最后四层的[CLS]标记平均化,以获得每条语句特征向量。
是RoBERTa中向量的隐藏状态的维度。我们将最后四层的[CLS]标记平均化,以获得每条语句特征向量。
2.2.3对话语境的表示
在对话场景下,一条语句的情感通常取决于整个对话的背景。因此,基于对话语句级别的特征![]() ,我们应用双向门控循环单元(Gated Recurrent Unit, GRU)来模拟相邻语句之间的顺序依赖关系,对话语境表征
,我们应用双向门控循环单元(Gated Recurrent Unit, GRU)来模拟相邻语句之间的顺序依赖关系,对话语境表征![]() 可以计算为:
可以计算为:
![]() = GRU(
= GRU(![]() ,
, ![]() )
)
其中![]() 代表时间步骤
代表时间步骤![]() 的隐藏状态向量,
的隐藏状态向量,![]() 是GRU单元输出的维度。
是GRU单元输出的维度。
2.2因果感知交互
为了获得更丰富的对话中的情感动态线索,并明确交互说话人内部和说话人之间的依赖关系,我们设计了两步的因果感知交互,包括因果线索检索和因果语句回溯,以丰富情感原因的语境表示。
2.2.1因果线索检索
为了探索目标语句的情绪原因在多大程度上取决于自身原因或他人原因的语句,我们应该检索自身和他人的因果线索,并给它们分配加权分数。对于自身因果线索的检索,我们主要关注来自同一说话人的影响或作用,检索分数可以计算为:
![]()
其中,![]() ,
, ![]() 和
和![]() 都是线性变换。
都是线性变换。![]() 确保目标语句
确保目标语句![]() 检索到与它相同的说话人的语句,以进行自身原因线索检索。值得注意的是,
检索到与它相同的说话人的语句,以进行自身原因线索检索。值得注意的是,![]() 保证了检索过程的正确时间顺序,这符合因果关系的本质,即不能根据未来的因果线索来寻找原因。
保证了检索过程的正确时间顺序,这符合因果关系的本质,即不能根据未来的因果线索来寻找原因。
![]()
其中![]() 是对话语句与其说话人的映射。
是对话语句与其说话人的映射。
他人间线索检索的过程中,要注意其他说话人的话语中所包含的线索。
![]()
![]()
一旦从自身和他人间线索中获得检索分数,我们就应该在同一尺度上综合考虑它们。控制应该从自身或他人间因果语句中收集多少信息的联合值可以通过以下方式计算出来:
![]()
2.2.2因果语句回溯
在因果语句回溯的步骤中,模型可以意识到不同的权重,根据因果线索检索得出的结果,更多地关注与情绪原因相关的语句。上述联合值被分解成两部分,由说话人自身和对方的轮次进行区分,表示为![]() 和
和![]() 。
。
然后,因果意识的语境表征与自身原因语句和他人间原因语句相结合,可以得到:
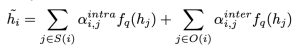
其中,![]() 是与语句
是与语句![]() 相同的说话人的语句集合,
相同的说话人的语句集合,![]() 代表说话人与语句
代表说话人与语句![]() 不同的语句集合。此外,因果线索中包含的情感信息也应被考虑在内:
不同的语句集合。此外,因果线索中包含的情感信息也应被考虑在内:
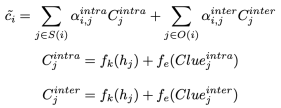
其中![]() 是一个线性变换。而最终的因果意识表示是通过以下方式拼接起来的:
是一个线性变换。而最终的因果意识表示是通过以下方式拼接起来的:
![]()
2.3情绪识别
最后,以上述因果感知表示为基础,应用情感分类器来预测语句的情感。
![]()
3.实验
3.1数据集
我们在IEMOCAP、DailyDialog和MELD三个基准数据集上进行了实验。这三个数据集的统计数据见下表。
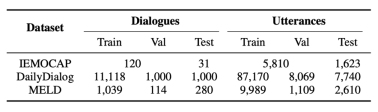
3.2 主实验结果及分析
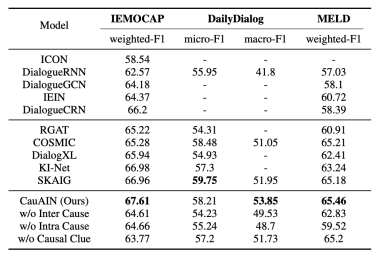
IEMOCAP包含了丰富的对话背景信息,平均对话长度达50个回合,而且在这个数据集中更频繁地观察到情绪动态变化现象。受益于情感原因检测以提取深层次的、丰富的情感动态线索,CauAIN在IEMOCAP上取得了67.61分的新的最高的分数。即使COSMIC也使用了的一些类似的外部知识,我们认为CauAIN比COSMIC表现更好的原因是,语句之间一步一步的顺序互动和缺乏对情感原因的考虑,阻碍了对对话语境中包含的丰富情感线索的理解。同时,我们的模型在DailyDialog上取得了最佳的宏观F1得分,这表明CauAIN可以部分地缓解数据不平衡的影响。
我们观察到,CauAIN在MELD上比最近的基线模型获得了轻微的改进。原因可能是MELD是一个具有短对话的多说话人数据集。因此,那些没有作用在当前说话人身上的对话语句会给情感原因检测带来噪音和无用的信息。这提醒我们要进一步纳入对话的话语结构,并在多方对话的背景下明确地建立对话线程模型。
3.3消融实验
为了研究情绪原因对情绪识别的影响,我们在模型中删除了自身原因和他人间原因的相关部分。具体来说,来自ATOMIC的因果线索被丢弃,我们不进行两步因果意识的交互。在所有三个数据集上的表现都有一定程度的下降,这在表2中倒数第二行和倒数第三行中显示。这表明,在为情感识别提供丰富的情感线索方面,内因和外因都起着重要作用。同时,这也体现了借助于内部和外部原因检测去实现明确的说话人内部和外部依赖关系模型的有效性。此外,值得一提的是,消融结果在MELD上表现出明显的差异,只考虑他人间原因会导致参加更多无用的上下文信息,使模型性能下降。这与第3.2部分的分析是一致的,对于多方对话应该考虑对话线程的额外信息。
为了验证生成的因果线索的有效性,我们首先分析了它对情绪原因检测的影响。由于IEMOCAP上没有标注情绪原因标签,我们从测试集中随机选择100段对话进行人工评估。从因果线索检索的输出中选择对应于前三个加权值的语句作为情绪原因的候选集。我们要求人类注释者判断真正的语句是否属于候选集。准确率被作为评价指标。在因果线索的帮助下,我们提出的模型的情感原因相关模块最终达到了60%的准确率。当放弃生成的因果线索时,因果意识的交互过程就会退化为对话话语之间的普通交互,情绪原因检测的准确率就会降低到53%。尽管与情绪原因相关的模块所产生的结果不够显著,但因果线索的引入确实有助于检测对话中准确的因果语句与情绪原因发现,而且整个过程不依赖于任何情绪原因的标注。
此外,因果线索对情感识别的影响见表2的最后一行。没有因果线索的模型意味着我们没有从COMET中引入生成的因果线索,对话语句间的交互只是在纯对话环境中进行。从前面的分析可以看出,引入的因果线索有助于模型更准确地检测情绪原因。而在ERC数据集上下降的结果不仅证明了情绪识别的性能得益于纳入准确的情绪原因,而且还显示了用因果线索中的潜在的情感信息来丰富语境表示的有效性。我们相信,如果有了情绪原因的真实标签,情绪识别和情绪原因检测都会有更好的表现。
4.结论
在本文中,为了捕捉更深层次和更丰富的情感动态线索,并明确建立说话人内部和说话人之间的依赖关系,我们提出了新颖的因果感知交互网络(CauAIN),用于对话中的情绪识别。更具体地说,我们探讨了在识别目标话语的情绪时,纳入情绪原因的有效性。常识知识作为因果线索被利用,以帮助自动提取情绪原因语句,并缓解因缺乏情绪原因真实标注而带来的限制。然后,我们设计了包括因果线索检索和因果语句回溯在内的两步因果感知交互过程,以检测与目标语句相对应的自身和他人间情绪原因,并获得因果感知的语境表示,以进行情绪识别。在三个基准数据集上的实验结果证明了我们所提出的CauAIN的有效性及其检测准确情绪原因的能力。
引用信息:
Weixiang Zhao, Yanyan Zhao, and Xin Lu. 2022. Cauain: Causal aware interaction network for emo- tion recognition in conversations. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, pages 4524–4530. ijcai.org.

赵伟翔,哈尔滨工业大学计算学部博士二年级在读,主要研究领域为对话情感,文本情感计算。

赵妍妍,博士,哈尔滨工业大学计算学部副教授、博士生导师,加州大学伯克利分校访问学者。研究方向为文本情感计算。近年来主持国家自然科学基金、教育部人文社科基金等多项基金项目。在人工智能、自然语言处理等领域国际期刊和会议上发表论文30余篇。曾获黑龙江省科技进步一等奖、黑龙江省科技进步二等奖、黑龙江省技术发明二等奖等。

陆鑫,哈尔滨工业大学计算学部在读博士生,主要研究方向为文本情感分析、对话情感。
