
论文链接:https://ieeexplore.ieee.org/document/9859836/
论文代码:https://github.com/skeletonNN/NHFNet
作者:付子旺、刘峰、许晴、齐佳音、傅湘玲、周爱民、李志斌
单位:北京邮电大学、华东师范大学、上海对外经贸大学
01 动机介绍
融合技术对于多模态情感分析至关重要。最近基于注意力的融合方法表现出高性能和强鲁棒性。然而,这些方法忽略了三种模态之间的信息密度差异,即视觉和音频具有低水平的信号特征,而文本具有高水平的语义特征。为此,我们提出了一种非齐次融合网络(NHENet)来实现多模态信息交互。具体而言,设计了一个具有注意力聚合的融合模块,用于处理视觉和音频模态的融合,以将其增强为高级语义特征。然后,使用跨模态注意来实现文本模态的信息增强和视听融合。NHFNet补偿了不同模式的信息密度差异,实现了它们的公平交互。为了验证该方法的有效性,我们分别在CMU-MOSEI数据集上进行了对齐和非对齐实验。实验结果表明,该方法优于现有方法。
02模型方法
在这项工作中,多模态情感分析任务包括三种主要方式,即文本(t)、视觉(v)和音频(a)。模型的输入是单模态原始序列来自同一视频剪辑。我们的目标是为对齐和未对齐形成高效融合多模态序列,聚集非齐次模态特征以实现情感预测。
2.1 模态编码
我们首先对多模态序列的输入Xm进行编码,转换为hm的长度表示。具体地说,我们使用BERT编码的最后一层的头部嵌入作为文本的原始特征。原始文本特征通过两层LSTM,将文本上下文时间信息聚合到ht的长度表示中。对于视觉和音频特征,我们使用全连接的网络。每个模态的上下文感知特征编码可以公式化如下:
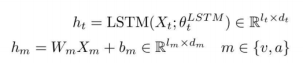
2.2 通过注意力聚合模块进行融合
考虑到音频和视觉模态是低级特征,而文本是具有高级语义特征的人类语言表达。为了克服语义鸿沟并使它们能够公平融合,我们提出了一种具有注意力聚合模块的低层特征融合机制。如图1所示。具体而言,下面,我们将跨模式流限制到网络的后几层,允许网络的前几层专门学习和提取单模态表示。
首先,我们使用Transformer编码器允许注意力在一个模态内独立流动,以进行单模态表示学习。编码器由一系列L个变换器层组成,每个变换器层由应用剩余连接的多头自关注(MSA)、层归一化(LN)和多层感知器(MLP)块组成。我们将变压器层表示为:
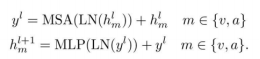
然后,我们通过注意力聚合模块进行低层特征融合。我们强迫一种模式在与另一种模式共享信息之前整理和浓缩其自身的信息模式。
这里,聚合模块被更新两次,一次使用视觉信息,然后使用音频信息。该操作允许模型压缩来自每个模态的信息并仅共享必要的信息,增加或保持多模态融合性能,同时降低计算复杂度。
2.3 跨模态注意力融合
跨模态注意操作使用以下信息:源模态通过学习源模态和目标模态之间的定向成对注意来增强目标模态。考虑到已经获得了视听融合的高级语义特征,我们使用跨模态注意操作来实现文本模态与视听融合的相互增强。我们定义了两个张量X和Y的跨模态注意,其中X表示查询,Y表示用于重新加权查询的键和值,即MCA(Xs,Xt;)=Attention(WQX,WKhm,WVhm)。
我们不断地在视听融合和文本模式之间交互跨模式注意,以获得彼此的增强特征。为此,我们定义了一个交叉变压器层:
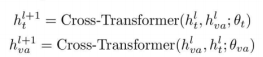
2.4 预测
最后,我们分别取原始文本特征ht,增强文本特征ht’,并且增强的视觉和音频融合特征hva’通过自注意机制得到最后一层头部嵌入输出。我们将这些头部嵌入输出与融合的视觉和音频特征的头部嵌入输出相加。通过一层完全连接的网络获得最终情感预测:
![]()
03 实验
3.1 数据集
CMU-MOSI和CMU-MOSEI是用于多模态情感分析的常用数据集。我们选择使用CMU-MOSEI来评估我们的方法,因为它由相同的作者提供,数据更多,并且是CMU-MOSI的升级版本。CMU-MOSEI数据集包含来自1000名不同演讲者的22852个带注释的视频剪辑(话语),以及来自在线视频共享网站的250个主题。每个话语都用情感强度进行注释。训练、验证和测试集分别包含16322、1871和4659个样本。在最近的工作中,我们评估了:1)回归的平均绝对误差(MAE)和皮尔逊相关(Corr),2)二元精度(Acc-2)和FI分数,3)七级精度(ACC7)。对于二元分类,我们认为[-3,0]标签为负,而(0,3]为正。
3.2 相关工作实验比较
我们将NHFNet与现有的最先进技术进行了比较。基线和结果如表1和表2所示,用于情绪分析的方法,包括MFM[20]、ICCN、MISA、对齐实验的MAF-BERT、TFN、LMF、自MM、MMIM、未对齐实验的GraphPage,以及满足两种设置的MulT、PMR、SPT。

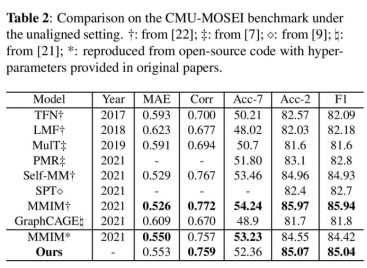
对于对齐设置,我们提出的方法优于所有基线。我们将现有方法分为几类:1)ICCN是一种使用深度CA将文本与视听相关的方法。NHFNet在Acc-7、Acc-2和F1得分中分别提高了1.5%、0.9%和0.8%。2) MulT、PMR和SPT都是基于跨模态注意力的融合架构,我们的方法比所有这些架构都有显著改进,FI度量提高了约2%。3) MISA利用模态不变性和特异性来完成融合。与此方法相比,NHFNet侧重于不同模态的语义表示,并取得了更出色的性能。4) 在现有的方法中,MAG-BERT具有最强的性能。然而,与之相比,我们提出的方法在精度方面实现了最先进的结果,而无需对BERT进行微调。这进一步证明了考虑不同模态信息密度的必要性。
对于未对齐的设置,我们提出的方法优于大多数基线。基于表2,我们可以得出以下结论:1)与基于跨模态注意力的模型(如MulT、PMR和SPT)相比,NHFNet具有更高的性能,Fl分数提高了约3%。2) TFN和LMF创建了融合模式的联合表示,与这些方法相比,我们的方法在F1得分上有大约2%的改进。3) Self-MM使用自监督和多任务进行表示学习。与之相比,NHFNet在Acc-2和FI评分方面提高了约0.1%。4) 我们使用原始论文中提供的超参数复制了高级MMIM,我们的方法在F1分数上提高了约0.6%。
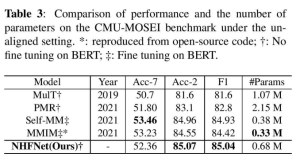
此外,我们还比较了几种竞争模型的效率。为了提供公平的比较,表3仅显示了融合网络的参数数量。1) 与MulT和PMR相比,我们提出的方法更轻量级,因为只使用了2个跨模态注意。NHENet通过将Fl分数分别提高约4%和3%实现了出色的性能。2) 与自MM和MMIM相比,NHENet在没有对BERT进行微调的情况下实现了出色的性能。由于它们在BERT上进行了微调,很明显,我们提出的方法的执行效率明显高于它们。
3.3 消融实验
表4显示了我们在校准设置中进行的消融研究。首先,我们进行单模态实验,以验证音频和视觉模态的低层次性质以及文本的高层次语义属性。具体而言,我们通过两层LSTM为三种模式中的每一种模式捕获时间特征。表4中的结果表明,基于BERT预训练的文本(未在CMU-MOSED上进行微调)已经取得了很好的性能,而视觉和音频单峰模态与文本单峰模态的Fl分数相差约20%。这证明视觉和音频特征是低级的,需要增强为高级语义特征,以便与文本进行公平的交互。
同时,我们验证了网络是否将视觉和音频模态从低级特征增强为高级特征。“A-V Fusion”表示将增强的音频-视频融合特征直接用于情感输出。可以看出,与单峰性能结果相比,改进了约10%,这表明该操作增强了音频-视频低电平信号特征,消除了冗余信息,并保留了有利于最终高电平特征用于情绪预测的特征。
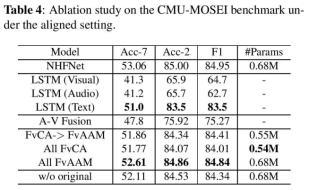
此外,我们验证了跨模态注意力融合(FvCA)和注意力聚合模块融合(FvAAM)的有效性。表4中的结果表明:1)FvCA->FvAAM表示使用FvCA进行音视频融合,使用FvAAM进行高级特征学习。结果表明,使用注意力聚合的FVAAM更有效,更适用于跨模态融合。2) “所有FvCA表明,使用跨模态注意来考虑模态信息密度的差异,可以得到类似的结果。与使用所有跨模态注意力的MulT相比,我们通过考虑这种可变性获得了更好的结果。3) 与其他情况相比,所有FVAAM通过使用所有注意力聚集实现了最佳效果,这进一步证明了该模块的卓越性能及其对跨模态信息传递的适用性。
此外,我们将原始模态信息(ht,hva)以残差的形式添加到预测阶段的最终结果中。我们用“w/o original”表示原始信息的删除。实验结果表明,在跨模态注意特征增强阶段,一些重要的原始特征可能丢失,这种缺失可以通过将原始特征相加来抑制。同时,我们通过网络中的自我注意操作将原有的特征放在网络中,这也在一定程度上增强了情态的特征。
04 结论
在本文中,我们提出了NHFNet来实现非齐次多模态信息交互。所提出的方法考虑了不同模态的信息密度差异,即视觉和音频是低级信号特征,而文本具有高级语义特征。首先,我们使用具有注意力聚集的融合模块来实现视觉和音频模态的低层特征增强。该模块克服了成对注意的次要复杂性,并提高了有效整合模态之间互补信息的能力。然后,我们使用跨模态注意来实现文本的高级语义特征的增强和高性能情感预测的视听融合。最后,对CMU-MOSEI在对齐和未对齐设置下的大量实验证明了所提出模型的有效性。
引用信息:
Ziwang Fu, Feng Liu, Qing Xu, iayin Qi, Xiangling Fu, Aimin Zhou, Zhibin Li. "NHFNET: A Non-Homogeneous Fusion Network for Multimodal Sentiment Analysis," 2022 IEEE International Conference on Multimedia and Expo (ICME), 2022, pp. 1-6, doi: 10.1109/ICME52920.2022.9859836.
通讯作者

刘峰,华东师范大学博士,上海对外经贸大学特邀研究员、人工智能与变革管理研究院区块链技术与应用研究中心主任,中国计算机学会高级会员,中国自动化学会区块链专委,中文信息学会情感计算专委,清华X-lab区块链创新教育计划合作委员会专委。主要研究兴趣在区块链、深度学习、数据科学等学科交叉领域。担任多个国内外核心学术期刊、国际会议、SCI/EI等国际特约编辑及审稿人。

齐佳音,上海对外经贸大学人工智能与变革管理研究院院长,教授、博士生导师,国家级人才称号获得者。围绕前沿技术与管理创新,主持完成国家重大/重点科研等十余项。七次入选爱思唯尔中国高被引学者, 担任中国信息经济学会副理事长、中国人工智能学会社会计算与社会智能专委会副主任,中国系统工程学会系统动力学专委会常务理事。
